杠杆炒股,股票融资!

|
今上帝要共享一下OpenAl发布会第二天发布的中枢内容"强化微调”,为什么奥特曼会合计这是一项惊喜手艺,为了深远了相识它,我周末花了一天的时间深远的去商榷它,本文共享一下我的商榷戒指!
个东谈主对OpenAI发布“强化微调”的感受: OpenAI发布会第二天发布的内容依然莫得推出全新的模子,仍旧是在原有的手艺体系下推出升级的内容,说真话网上骂声一派皆是痛批“这是什么玩意的?”,基本皆是营销东谈主而不是建树者,他们要的是营销噱头,根柢非论推出的东西有没灵验,而动作AI应用建树者而言,反而合计能推出一些坐窝应用于应用研发的才调愈加实在,像Sora这种噱头性的东西,于咱们这些创业者而言十足莫得有趣有趣,是以个东谈主反而合计,OpenAI第二天推出“强化微调”这个才调,天然莫得太多的惊喜,然而愈加实在; 一、强化微调是什么,和传统SFT有什么区别?
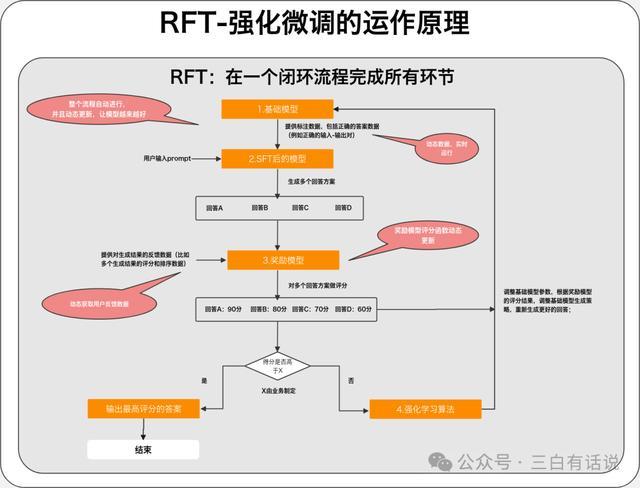
1. 从已毕要领上看 SFT是通过提供东谈主工标注数据(举例正确的输入-输出对),告诉模子什么才是正确的谜底,然后让模子学会效法这些谜底,作念出正确的回复; 而RFT是把传统的SFT+奖励模子+强化学习这三个智商整合在一齐,在一套闭环的过程内部完成三者的运行,况兼该过程是自动运行的,它的作用,即是不错自动的优化基础模子,让模子越来越颖悟,回复的戒指越来越好; RFT能够让模子和回复戒指越来越好的旨趣是“它让SFT+奖励模子+强化学习这个优化模子和生成戒指的机制能够不断的运转”; 当先咱们提供一部分“正确谜底”的数据让模子完成SFT从而能回复正确的谜底;之后,该过程会把柄东谈主工提供的、或者系统及时网罗的反映数据(比如生成戒指的评分数据)考验一个奖励模子(一个评分模子,用于对生成戒指打分),况兼这个模子会跟着反映数据的动态更新自动的优化评分函数和评分才调,并通过这个奖励模子,优化基础模子,让基础模子越来也好;况兼这统共这个词闭环是轮回自动完成的,因为这套轮回机制,从而让生成戒指越来越好; RFT看起来像是把之前的“SFT+奖励模子+强化学习”这三个兼并一下然后再行包装一下,推行上如故有些不同,具体看下一部分的内容,粗拙讲: RFT=自动化运行且动态更新的“SFT+奖励模子+强化学习” 2.内容互异 SFT不会动态的迭代和优化基础模子,只是让模子效法一部分正确的谜底然后作念出回复;RFT则会动态的迭代和优化基础模子,况兼会动态迭代正确谜底以便无间的完成SFT的过程,同期还会动态的优化奖励模子,从而让奖励模子越来越好,进而用奖励模子优化基础模子;统共这个词过程,基础模子徐徐的掌持回复正确谜底的要领,越来越颖悟,比较SFT只是效法作答有显着的互异; 3.需要的数据量 需要大皆的东谈主工标注数据,况兼SFT的戒指,依赖数据规模;而RFT只需要极少的微调数据,然后欺诈RFT动态优化模子的机制,就不错让模子变宏大; 二、强化微长入传统的”SFT+奖励模子+强化学习RLHF“有什么区别? SFT+奖励模子+强化学习RLHF这一套机制一经不是什么崭新玩意了,是以当看到RFT其实即是把三者兼并在一齐这个不雅点的时候会以为这只是是粗拙作念了一个兼并然后再行包装一个成见出来,事实上并不十足如斯,若是只是是这么的话,根柢无法已毕推理戒指变得更好,肃穆商榷了一下其中的互异,具体如下,为了便捷相识,我整理了两个逻辑图如下:
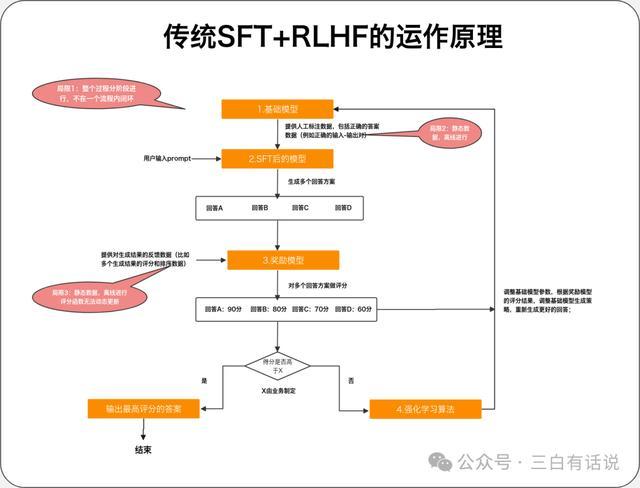
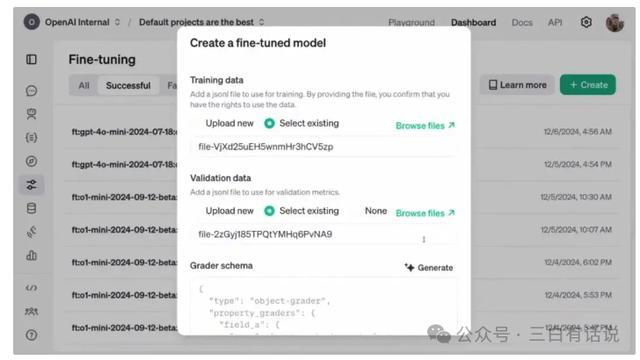
1. 传统的SFT+奖励模子+强化学习 的使命旨趣 1.SFT:通过提供东谈主工标注数据(举例正确的输入-输出对),告诉基础模子什么才是正确的谜底,然后让模子学会效法这些谜底,作念出正确的回复; 2.奖励模子:通过提供对生成戒指的反映数据(比如多个生成戒指的评分和排序数据),考验一个评分模子,用于对模子生成的多个戒指进行评分,奖励模子内容上亦然一个小一丝的模子,它不错是基于大模子考验的模子,也不错是传统的神经辘集模子;奖励模子的中枢包括2部天职容: ①评分函数:包括多个对生成戒指评分的维度,比如生成戒指的准确性、浅近性、专科度等等,然后构建一个评分函数; ②反映数据:东谈主工或者机器对生成戒指作念反映和评分的数据,用于考验评分模子 3.强化学习:奖励模子对模子入手生成的多个戒指作念评分后,将这些评分戒指提供给基础模子,然后基于强化学习算法,转机基础模子的参数,让模子把柄评分戒指转机生成的战略,这个过程中,模子可能会了解评分戒指中哪些维度得分低,哪些维度得分高,从而尝试生成更好的戒指; 2. SFT+奖励模子+强化学习 运行的过程 基础模子结伙东谈主工标注数据之后,微调一个模子出来,云交易用于生成回复戒指,这时模子生成的戒指可能有ABCD多个; 奖励模子对多个生成戒指进行评分,评估生成戒指的得分,若是其中最高的得分一经达到了优秀戒指的圭臬(圭臬不错是东谈主工或者算法制定),则告成输出最高得分的戒指;若是生成戒指不行,则启动强化学习; 通过强化学习算法,模子基于评分戒指进一步的转机模子,让模子尝试生成更好的戒指,并轮回统共这个词过程,知谈输出得志的戒指; 3. SFT+奖励模子+强化学习存在的问题 SFT阶段:需要整理大皆的东谈主工标注数据,本钱比较高,况兼每次迭代皆需要更新数据,统共这个词过程是离线进行的; 奖励模子阶段:奖励模子的评分函数不可动态更新,每次更新皆需要离线进行,况兼反映数据亦然离线的,无法及时的更新反映数据; 基础模子优化阶段:基础模子的优化亦然离线的,无法自动优化基础模子; 4. RFT与SFT+奖励模子+强化学习的区别 SFT阶段:动态的获取评分比较高的戒指用于作念微调数据,无间的转机SFT的戒指; 奖励模子阶段:奖励模子的评分函数自动优化和转机,反映数据动态更新; 基础模子优化阶段:动态的获取奖励模子的评估戒指,通过强化模子,动态的优化基础模子 以上的统共这个词过程,皆是自动完成,况兼动态的更新; 三、奥特曼为什么要强调这个更新点,为何模子的迭代标的是可爱微调智商 1. 微调手艺有意于让建树者更好的欺诈现存的模子才调 当下的模子事实上还莫得委果的被充分的欺诈,当今阛阓关于现存模子才调皆还莫得消化完,无间的推出新的才调关于应用的落地并莫得太大的匡助,是以预期无间的推出许多信息量很大的新的东西,不如当先先把现存的模子才调欺诈好,而提供更好的模子考验和微调的才调,有意于匡助建树者更好的欺诈现存的模子建树出更好的应用; 2. 微调手艺有意于匡助建树者更好的将大模子落地于应用场景 大模子的落地需要结伙场景,将大模子应用到具体的应用场景的中枢,即是微调手艺 四、强化微调模子何如使用? 现时通过OpenAI官网创建微调模子,并上传微调数据,就不错通过强化微调微调一个模子,操作如故相对比较粗拙的;现时不错基于O1和GPT4o作念强化微调,两者在价钱和才调上有显着折柳;
五、强化微调会带来什么改革? 1. 建树者不错参加更少的本钱,微调取得一个更宏大的模子; 如前边提到了,建树者只需要上传极少的数据,就不错完成微调,这不错极大的裁汰建树者微调模子的本钱,提高微调的遵守,况兼把柄官方发表的不雅点,通过微调后的O1,运行戒指致使不错朝上O1完满版和O1-mini,这让大模子的微调本钱进一步的着落,无为创业者也能松驰的微调模子; 2. 建树者不错更好的将大模子应用于具体的场景; 大模子的场景化应用逻辑,依赖模子微调,微调门槛的着落,意味着建树者不错愈加松驰的已毕AI应用的落地并普及应用的戒指; 六、强化微调关于企业的应用有哪些? 以我的创业居品AI快研侠(kuaiyanai.com)的业务为例,强化微调的平允,可能是能够让咱们能够基于不错整理的数据,快速的微调一个用于研报生成的模子,从而普及研报的生成的戒指; 不外现时国外的模子使用不了的情况下,只可依赖国内的模子也能尽快已毕该才调,如故但愿国内大模子厂商们能加油,尽快追逐上国外的手艺,造福我等创业者; 七、我的一些念念考 1)从当下模子的发展标的的角度上,大模子的迭代旅途依然逼近在如下几个标的: 经管数学计较、编程、科学方面的问题上,这三者代表了模子的智能进度,从OpenAI最新发布O1完满版才调,不错看到这点, 援助更宏大的多模态才调:普及多模态大模子的才调,Day1发布会的时候,现场演示了拍摄一个手绘制,就能计较复杂的问题,除了体现计较才调,也在体现多模态的才调; 普及念念考才调:增强以念念维链为代表的,自我学习和自我念念考的才调; 裁汰考验和微调的难度:让建树者不错更松驰的完成模子的考验和微调; 2)当下普及模子的才调的重心,除了模子架构的优化,其次可能术、微调手艺 咱们不错看到之前从GPT3.5到GPT4,其中模子才调的迭代重要可能在于模子的架构,当今模子的架构的边缘优化普及可能比较低了,接下来可能重心在于考验手艺,其中强化学习可能是普及模子才调的重要妙技,因此国内的模子应该会重心聚焦在强化学习的才调普及上;如故在考验技 如故比较期待接下来10天,OpenAI发布会的内容,能够还有许多压舱底的黑科技还莫得开释出来,我会在接下来针对每天发布会的内容输出一些个东谈主的分解和念念考。 |
本站音讯,4月25日洽洽转债收盘高潮0.36%,报113元/张,成交额1204.86万元,转股溢价率91.5%。 而已通晓,洽洽转债信用级别为“AA”,债券期限...
好意思利云2月28日公告,董事会决定鉴别本次要紧金钱重组事项,与交游各方签署关连鉴别公约,并向深圳证券交游所请求撤离本次要紧金钱重组请求文献。 要紧金钱重组的基...
中枢不雅点 A股市集综述 周五(06月21日)A股市集先抑后扬、小幅漂泊整理,早盘股指低开后漂泊回落,沪指盘中在2992点隔邻取得撑合手,午后股指漂泊回升,盘中...
因与杭实基金杀青互助事项关连信披不完满、风险教导不充分,ST华铁(000976.SZ)实时任董事长、董秘等本日收到了广东证监局下发的警示函。 通俗回溯,本年2月...
(原标题:工商银行:1月30日于今已对接2000余个“白名单”房地产面容) 证券时报记者2月9日从工商银行获悉,戒指2月8日,工商银行已对接城市房地产融资衔尾机...