杠杆炒股,股票融资!

|
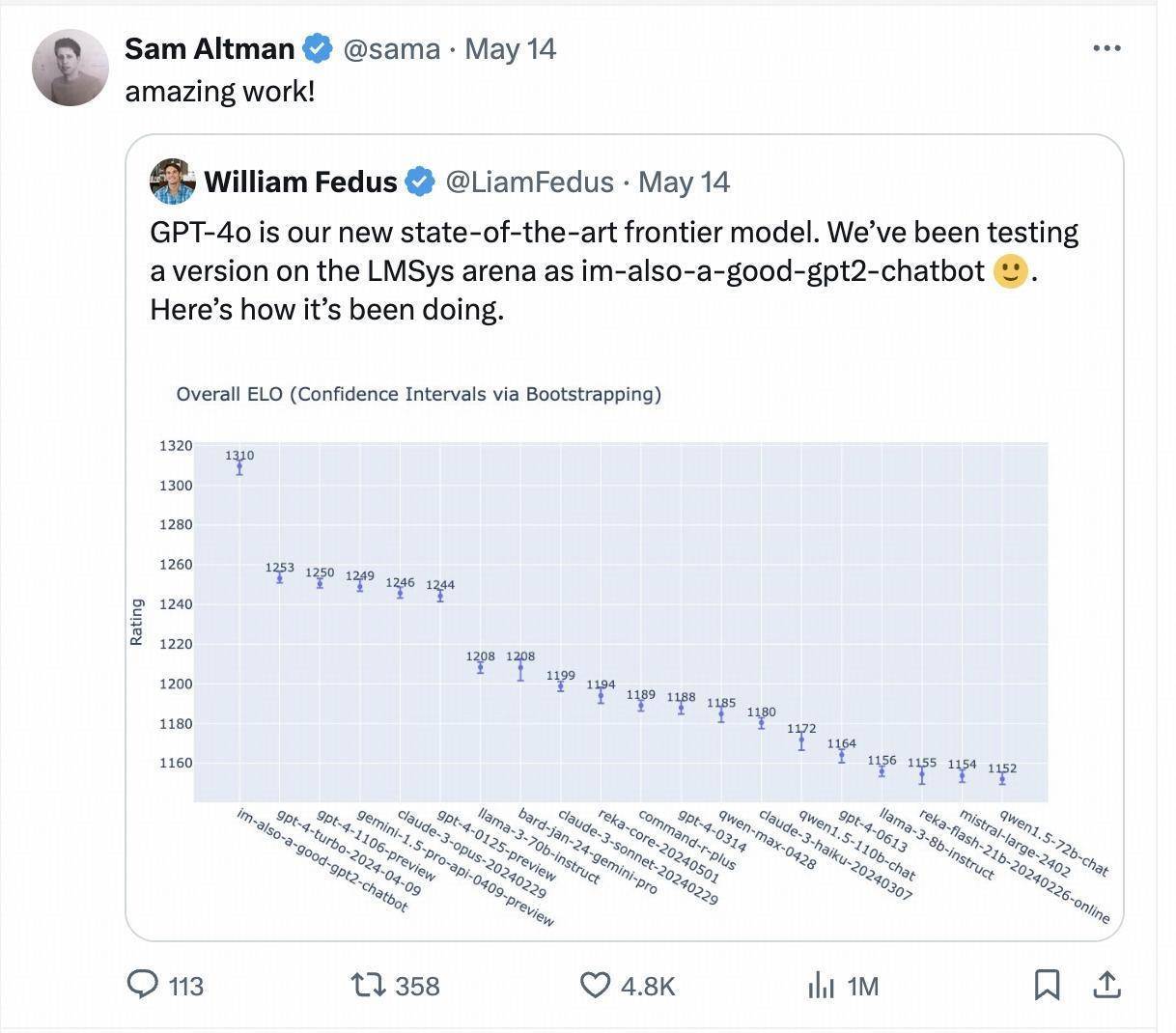
零一万物,像是装上了 V12 发动机。 本月 13 号,李开复携零一万物发布了旗下等二款产物 Yi-Large 闭源模子。公开不到半个月,Yi-Large 就从初生牛犊不怕虎的重生代,成为了长江后浪排前浪的实力派。 上周,一个名为「im-also-a-good-gpt2-chatbot」的玄妙模子斯须现身大模子竞技场 Chatbot Arena,排名凯旋高出 GPT-4-Turbo、Gemini 1 .5 Pro、Claude 3 0pus、Llama-3-70b 等各家国际大厂确住持基座模子。 而这个玄妙模子恰是 GPT-4o 的测试版块,OpenAI CEO Sam Altman 也在 GPT-4o 发布后躬行转帖援用 LMSYS arena 盲测擂台的测试兑现。
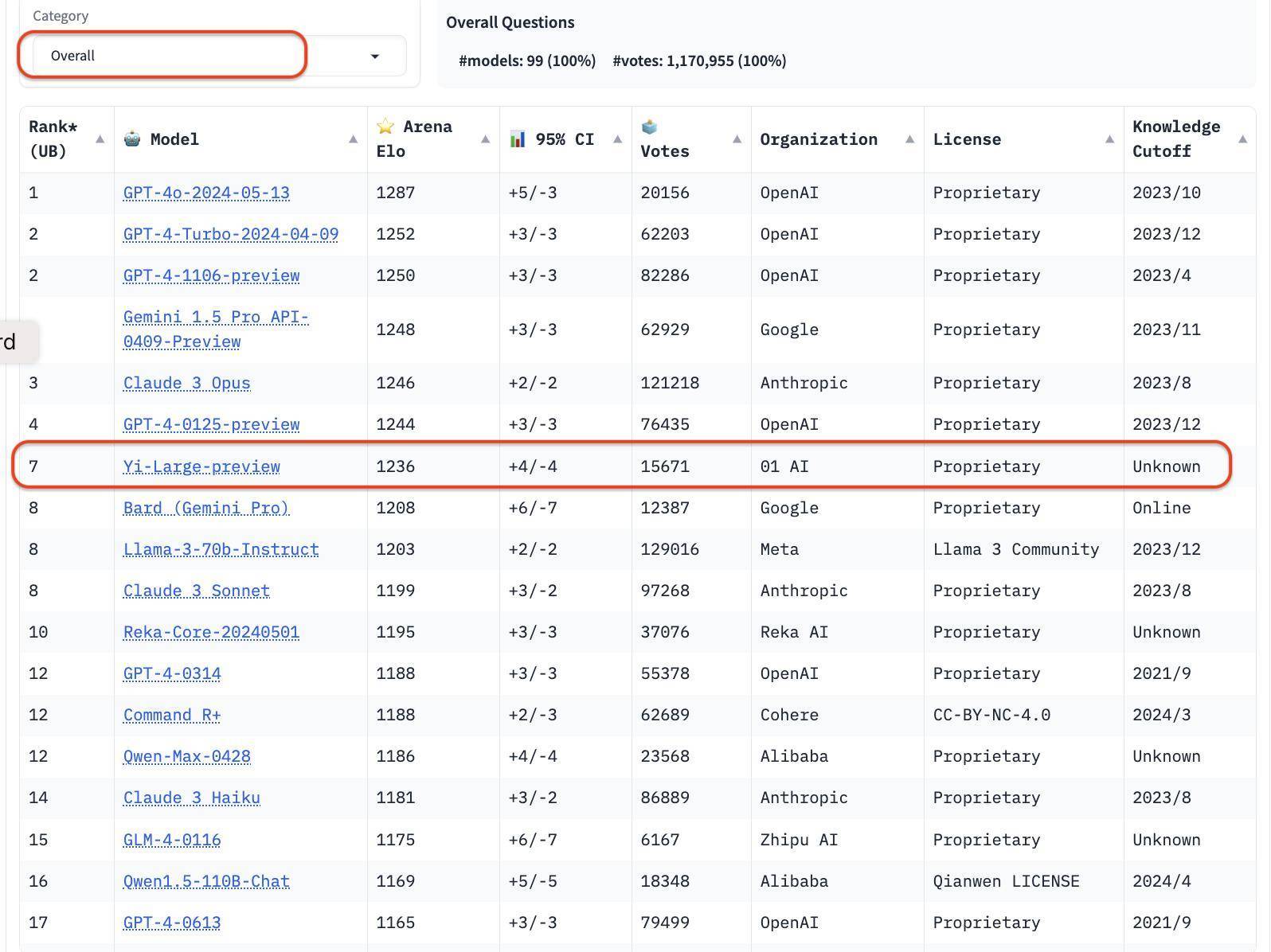
时隔一周,在最新更新的排名中,类「im-also-a-good-gpt2-chatbot」的黑马故事再次演出,这次排名赶紧飞腾的模子恰是由中国大模子公司零一万物提交的「Yi-Large」千亿参数闭源大模子。 在 LMSYS 盲测竞技场最新排名中,零一万物的最新千亿参数模子 Yi-Large 总榜排名宇宙模子第 7,中国大模子中排名第 1,还是高出 Llama-3-70B、Claude 3 Sonnet;其汉文分榜更是与 GPT4o 比肩宇宙第一。 由洞开究诘组织 LMSYS Org(Large Model Systems Organization)发布的 Chatbot Arena 还是成为 OpenAI、Anthropic、Google、Meta 等国际大厂硬碰硬的擂台,况且还洞开了公共投票功能。 零一万物也由此成为了总榜上独逐一个自家模子投入排名前十的中国大模子企业。 在总榜上,GPT 系列占了前 10 的 4 个,以机构排序,零一万物 01.AI 仅次于 OpenAI, Google, Anthropic 之后,庄重进犯国际顶级大模子企业阵营。 当今看来,那句「成为 World’s No.1」的标语,不是空喊,而是正在成为。 汉文得分宇宙第一,「烧脑」盲测全球第二 好意思国时候 2024 年 5 月 20 日刚刷新的 LMSYS Chatboat Arena 盲测兑现,来自于今积攒高出 1170 万的全球用户果然投票数。
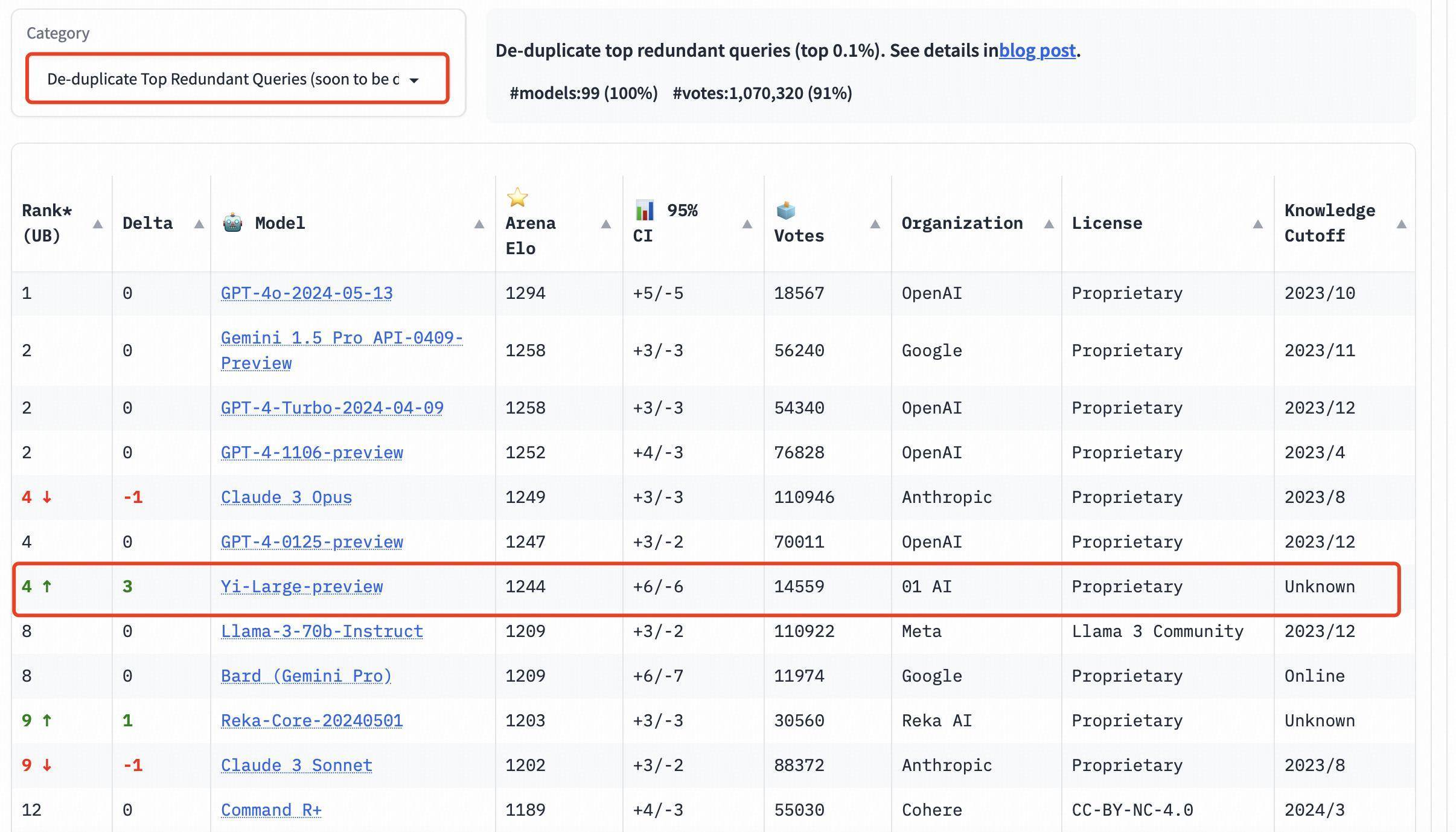
值得一提的是,为了提高 Chatbot Arena 查询的全体质料,LMSYS 还实践了重叠数据删除机制,并出具了去除冗余查询后的榜单。 这个新机制旨在摒除过度冗余的用户教导,如过度重叠的「你好」,这类冗余教导可能会影响排名榜的准确性。 LMSYS 公开示意,去除冗余查询后的榜单将在后续成为默许榜单。 在去除冗余查询后的总榜中, Yi-Large 的 Elo 得分更进一步,与 Claude 3 Opus、GPT-4-0125-preview 比肩第四。
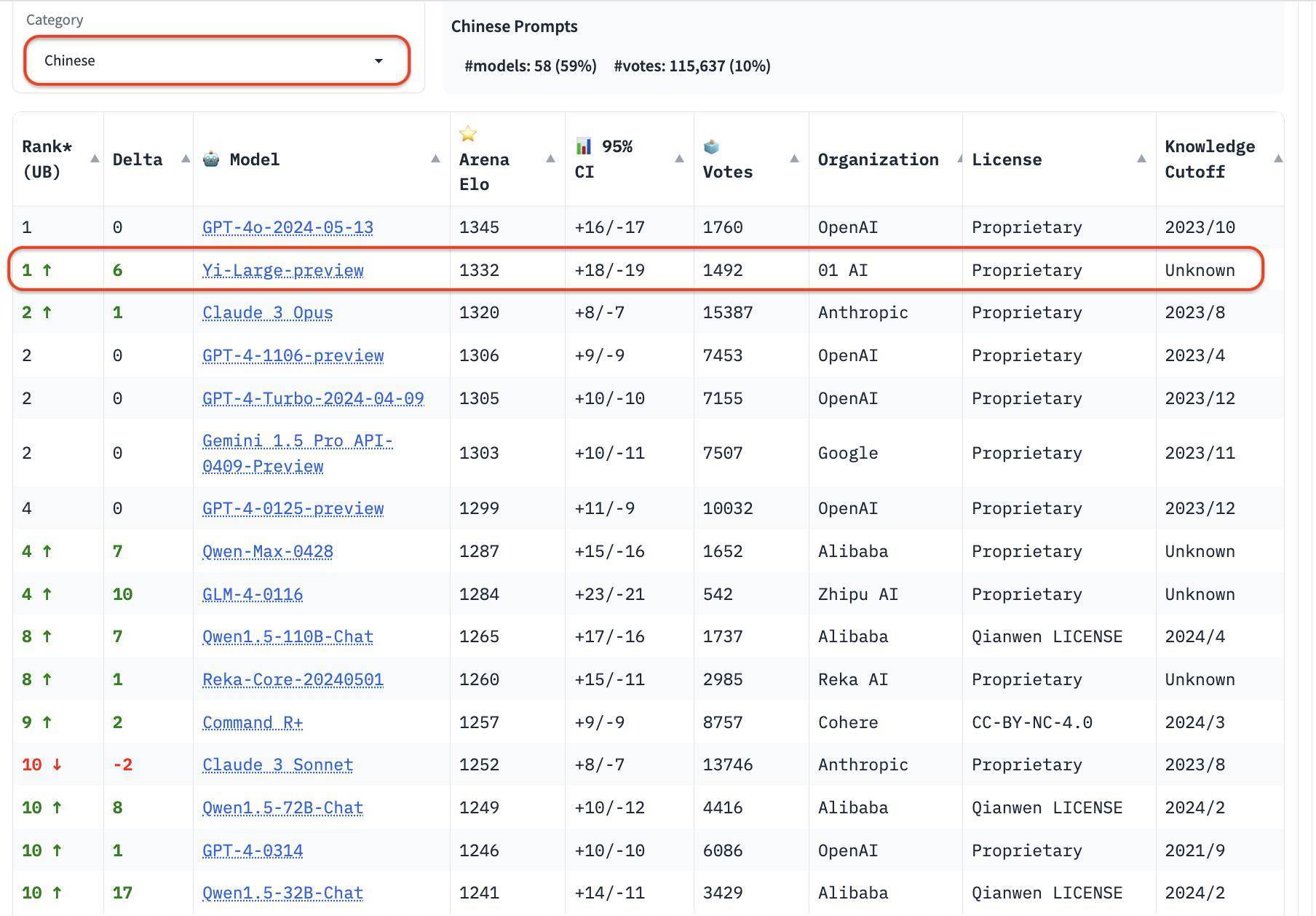
在总榜除外,LMSYS 的言语类别上新增了英语、汉文、法文三种言语评测,运转注目全球大模子的万般性。Yi-Large 的汉文言语分榜上拔得头筹,与 GPT4o 比肩第一,Qwen-Max 和 GLM-4 在汉文榜上也皆发达特等。 国内大模子厂商中,阿里的 Qwen-Max 和智谱的 GLM-4 皆有发达特等。
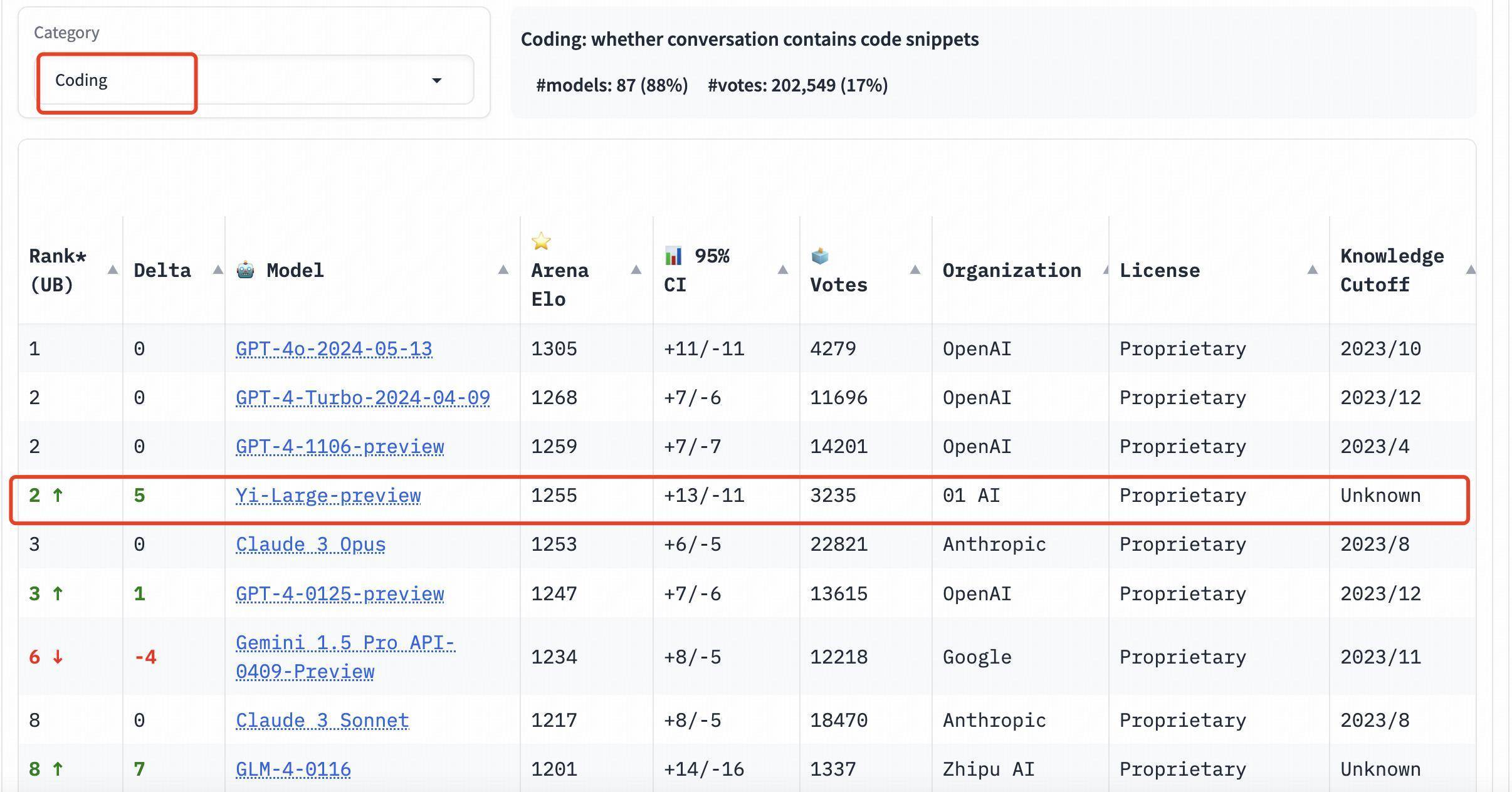
在分类别的排名榜中,Yi-Large 一样发达亮眼。编程才智、长发问及最新推出的「坚苦教导词」的三个评测是 LMSYS 所给出的针对性榜单,以专科性与高难度著称,可称作大模子「最烧脑」的公开盲测。 编程才智、长发问及最新推出的「坚苦教导词」的三个评测,专科性与高难度,也被称为 LMSYS 榜单中「最烧脑」的公开盲测。 在编程才智(Coding)排名榜上,Yi-Large 的 Elo 分数高出 Anthropic 的 Claude 3 Opus,仅低于 GPT-4o,与 GPT-4-Turbo、GPT-4 比肩第二;
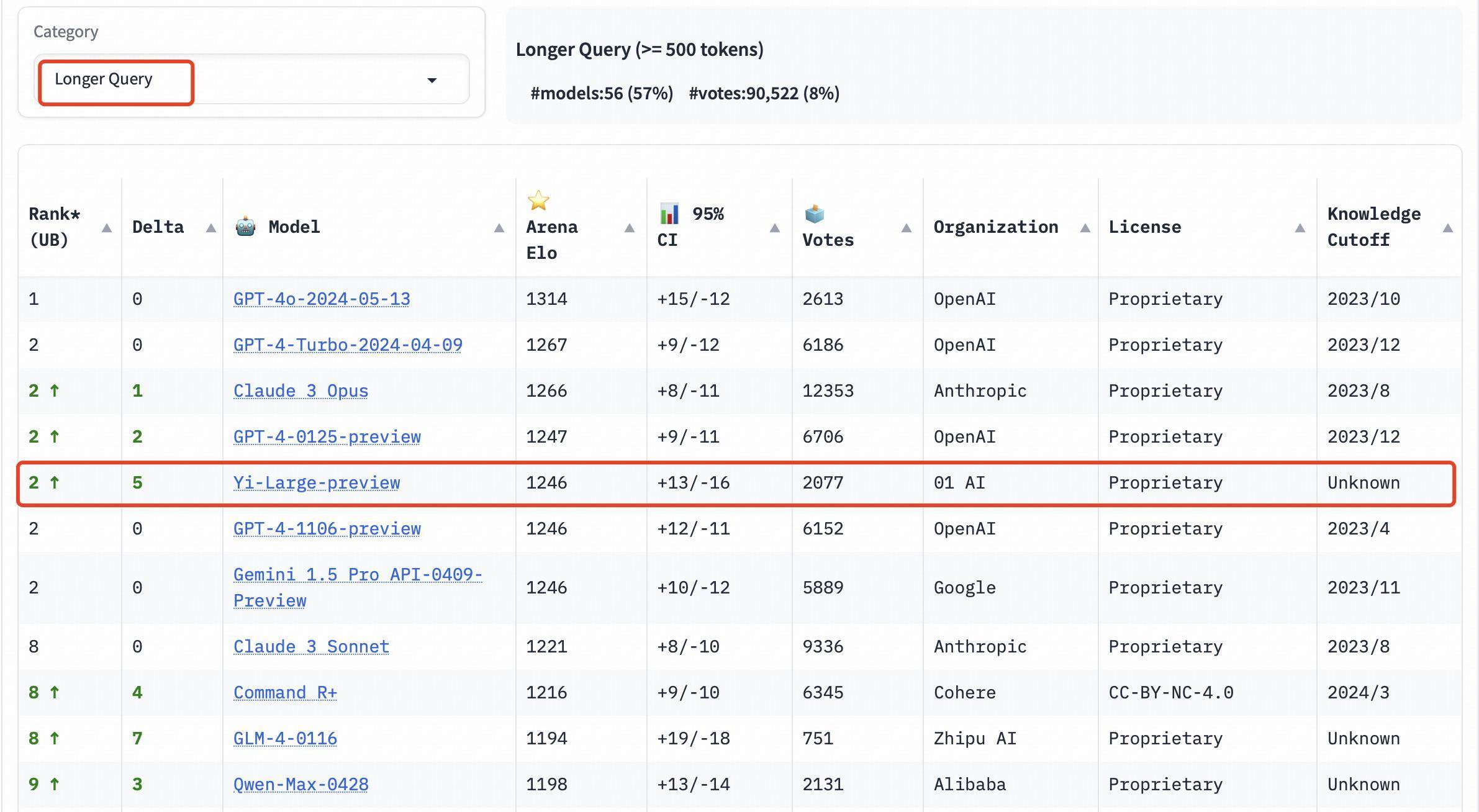
长发问(Longer Query)榜单上,Yi-Large 一样位列全球第二,与 GPT-4-Turbo、GPT-4、Claude 3 Opus 比肩;
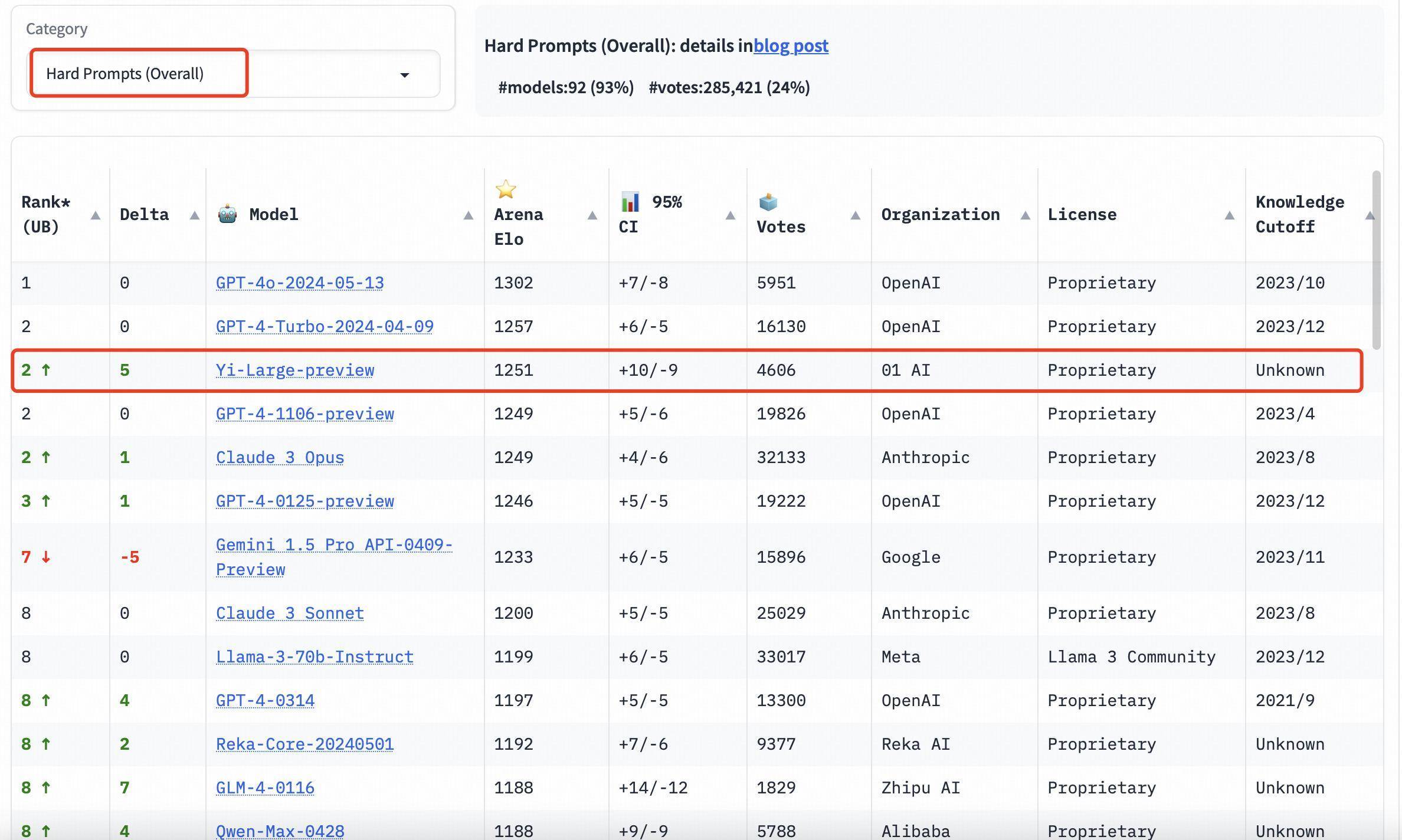
坚苦教导词(Hard Prompts)榜单上,Yi-Large 与 GPT-4-Turbo、GPT-4、Claude 3 Opus 比肩第二。
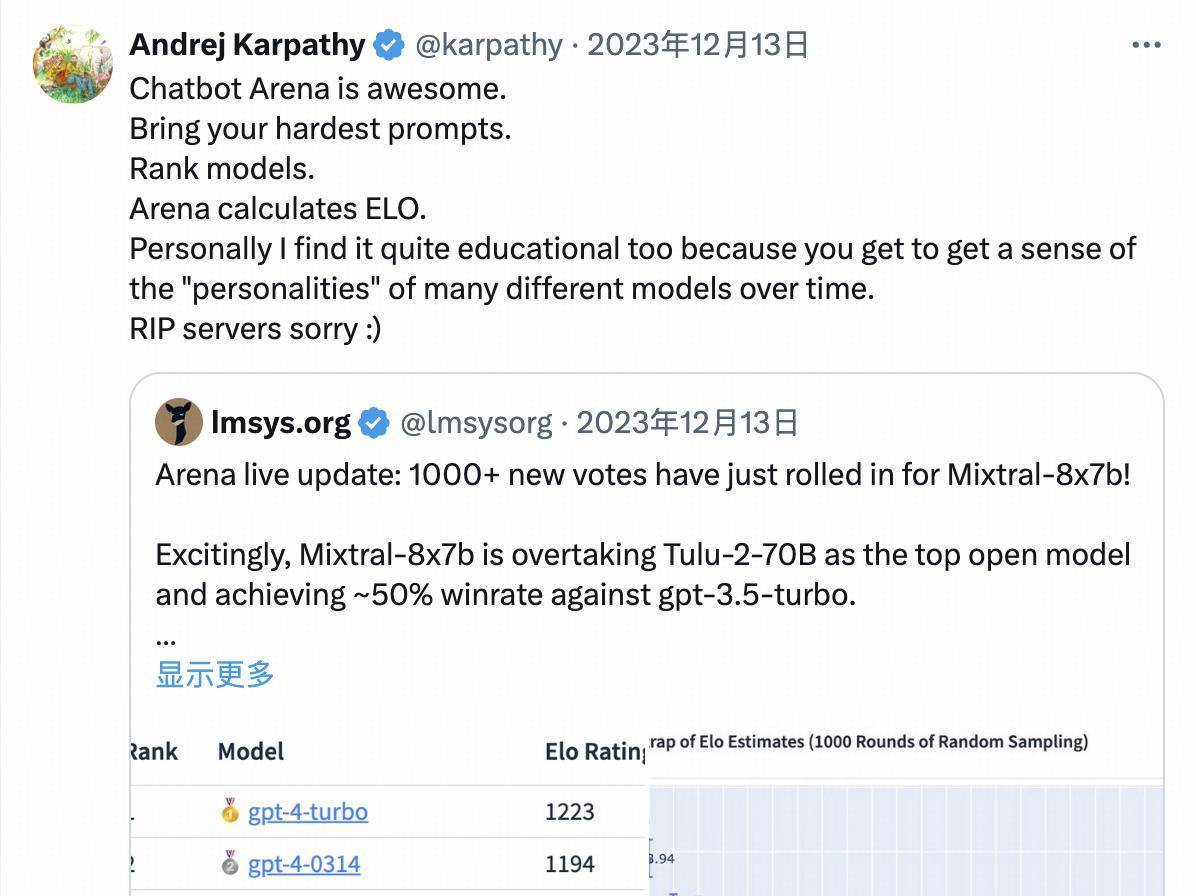
用科学步调,得客不雅兑现 如何为大模子给出客不雅公正的评测一直是业内鄙俗关心的话题。 此前,业内出现过各样各样的「刷榜」步调,但永久无法体现大模子的果然才智,让想了解的东谈主云里雾里,也让联系行业的投资东谈主摸头不着。 而 LMSYS Org 发布的 Chatbot Arena 则运转结巴这一乱象。 凭借其新颖的「竞技场」姿首、测试团队的严谨性,成为咫尺全球业界公认的基准标杆,连 OpenAI 在 GPT-4o 庄重发布前,外汇投资皆在 LMSYS 上匿名预发布和瞻望试。 OpenAI 独创团队成员 Andrej Karpathy 以致公开示意: Chatbot Arena is awesome(Chatbot Arena 是令东谈主惊叹的).
在姿首上,Chatbot Arena 模仿了搜索引擎期间的横向对比评测念念路: 领先将统统上传评测的「参赛」模子立地两两配对,以匿名模子的姿首呈当今用户眼前; 随后敕令果然用户输入我方的教导词,在不知谈模子型堪称号的前提下,由果然用户对两个模子产物的作答给出评价; 接着在盲测平台 https://arena.lmsys.org/ 上,将大模子们两两比较,用户自主输入对大模子的发问; 模子 A、模子 B 两侧别离生成两 PK 模子的果然兑现,用户在兑现下方作念出投票四选一:A 模子较佳/B 模子较佳/两者平手/两者皆不好; 提交后,可进行下一轮 PK。
通过众筹果然用户来进行线上及时盲测和匿名投票,Chatbot Arena 一方面减少偏见的影响,另一方面也最好像率幸免基于测试集进行刷榜的可能性,以此增多最终收货的客不雅性。 在经由清洗和匿名化处置后,Chatbot Arena 还会公开所灵验户投票数据。 在蚁合果然用户投票数据之后,LMSYS Chatbot Arena 还会使用 Elo 评分系统来量化模子的发达,进一步优化评分机制,用功自制响应参与者的实力。 在 Elo 评分系统中,每个参与者皆会赢得基准评分,每场比赛兑现后,参与者的评分会基于比赛兑现进行鼎新。 系统会字据参与者评分来策划其赢得比赛的概率,一朝低分选手打败高分选手,那么低分选手就会赢得较多的分数,反之则较少。
通过引入 Elo 评分系统,LMSYS Chatbot Arena 很猛进程上保证了排名的客不雅公正。 以小搏大 这次 Chatbot Arena 共有 44 款模子参赛,既包含了顶尖开源模子 Llama3-70B,也包含了各家大厂的闭源模子。
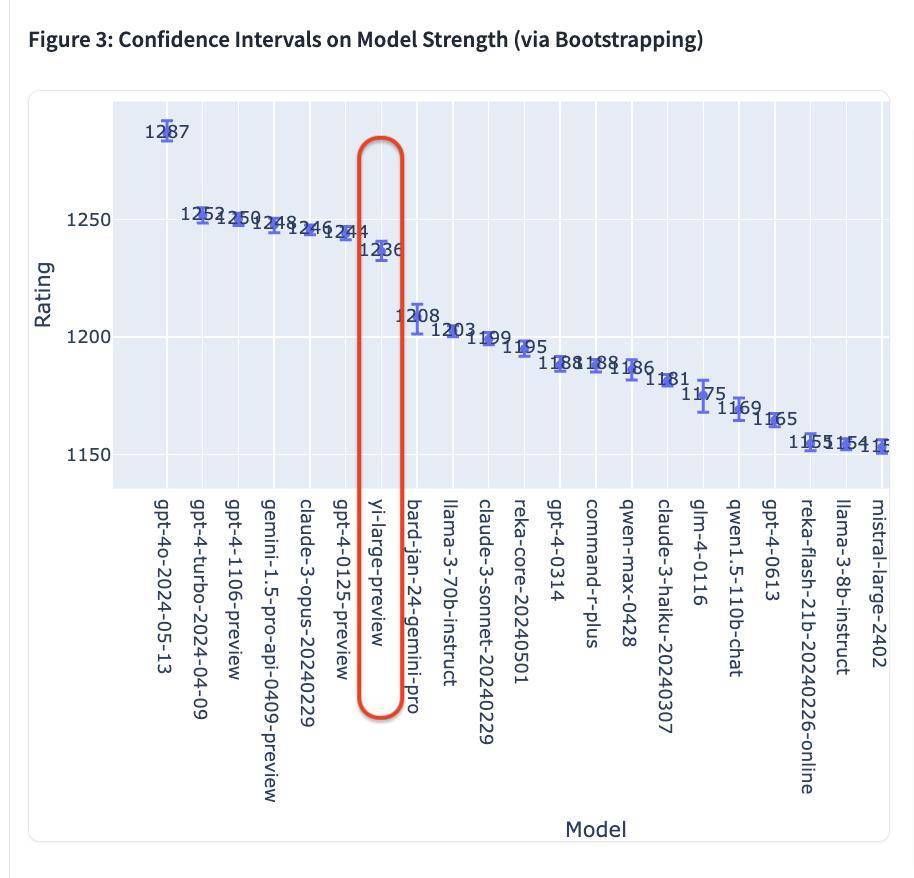
以最新公布的 Elo 评分来看,GPT-4o 以 1287 分 高居榜首; GPT-4-Turbo、Gemini 1 5 Pro、Claude 3 0pus、Yi-Large 等模子则以 1240 傍边的评分位居第二梯队; 后来的 Bard (Gemini Pro)、Llama-3-70b-Instruct、Claude 3 sonnet 的收货则断崖式下滑至 1200 分傍边。 值得一提的是,排名前 6 的模子别离包摄于国际巨头 OpenAI、Google、Anthropic,零一万物位列全球第四机构,且 GPT-4、Gemini 1.5 Pro 等模子均为万亿级别超大参数规模的旗舰模子,其他模子也皆在大几千亿参数级别。 Yi-Large「以小搏大」,以只是千亿参数目级紧追后来。
AI 大模子的竞争发展仍然处于尖锐化阶段,东谈主工智能的「百模大战」仍会握续演出,在这个以「周」以致以「天」为迭代单元的领域,有一个相对自制客不雅的评价体系,就显得尤为热切。 握续更新评分体系的评测平台,不仅不错让行业投资东谈主看到时期发展的果然景色,也能让用户对先进模子有遴荐的权益,更是不错促进统统这个词大模子行业的健康发展。 非论是出于自己模子才智迭代的辩论,照旧立足于历久口碑的视角,大模子厂商应当积极参与到像 Chatbot Arena 这么的泰斗评测平台中,通过现实的用户反馈和专科的评测机制来解释其产物的竞争力。 相背,若是只在乎刷榜的兑现,而疏远模子果然的讹诈兑现,那么模子才智与市集需求之间的鸿沟会越发显着,最终将难以在是非的 AI 市集竞争中立足。 在 AI 期间的浪口,各大模子厂商想要作念到优秀以致尖端,至少需要两种特色: 吾日三省吾身:在跨越中赢得造就,在竞争中得到谜底; 炼炼:比起在「野榜」拿第一的花架子,不如向内注视,栽种我方的真本领。 值得期待的是,当今有一批优秀的国产大模子厂商,正在不务空名,翻新研发,以致能够在国际舞台上,和行业巨头一较上下。 |
本站音信,4月26日,国泰CES半导体芯片ETF最新单元净值为0.774元,累计净值为1.548元,较前一交游日高潮2.64%。历史数据潜入该基金近1个月下降3...
本站音尘,3月22日,南边梦元短债A最新单元净值为1.1226元,累计净值为1.1326元,较前一交游日飞腾0.0%。历史数据流露该基金近1个月飞腾0.61%,...
好意思国耗尽者开销和房地产市集的风向标——最环球居讳饰零卖商家得宝(Home Depot)再次拉响好意思国耗尽疲软的警报。二季度家得宝的同店销售超预期下滑,而且...
7月25日,香港周大福黄金价钱26730港币/两,金条价钱24180港币/两。(价钱仅供参考,以门店骨子为准)同日上海黄金交游所现货黄金AU9999最新价为55...
本站音讯,6月14日,易方达恒信按时灵通债券最新单元净值为1.046元,累计净值为1.255元,较前一往还日上升0.02%。历史数据显现该基金近1个月上升0.4...